


Ever since organizations have realized the importance of software quality assurance, metadata tagging has become a common practice.
It’s obvious that as your software grows in size and complexity, managing test cases, along with defects and requirements, can become overwhelming. Especially if it’s being done without contextual data.
What metadata tagging does is provide a structured method to categorize, trace and filter these elements. This enables QA teams to increase visibility and improve decision-making.
Research on data governance & quality management, published by Bruno Miguel Vital Bernardo and others, shows that metadata management/tagging enhances data quality and governance by over 40%. Leading to better software compliance and efficiency in test execution workflows.

That said, we’ll discuss all about software QA metadata tagging in this article. So stick around.
Key Takeaways
- Metadata is needed for managing complexity. As software grows, metadata tagging provides a structured way to categorize and filter test cases, defects and requirements, leading to better decision-making for QA teams.
- It significantly improves data quality. Using metadata management/tagging can enhance data quality and governance by over 40%, which results in better software compliance and more efficient testing workflows.
- There are three main types of metadata. These are Descriptive (e.g., test type, priority), Administrative (e.g., ownership, timestamps), and Provenance (e.g., history of changes). All three are essential for the management, retrieval and auditability of testing assets.
- Priority tags focus your efforts. Assigning a Priority tag (high, medium, low) is crucial for QA teams to concentrate limited resources on the most critical functionalities and address severe issues promptly.
- Automation is key for enterprise scale. When your volume of tags exceeds 1,000, manual methods become challenging. This makes it necessary to switch to automated bulk tagging tools and tag normalization protocols to maintain a scalable and responsive system. (Manual tagging is sufficient for smaller scales with fewer than 1,000 tags.)
What Exactly Is Metadata Tagging?
Put simply, metadata tagging is the systematic assignment of descriptive information. The information we’re talking about is known as metadata itself, and it is tagged to software QA artifacts. These artifacts can be test cases, defects, requirements, etc.
This metadata provides context beyond just the raw figures. Due to this, dynamic grouping and traceability are enabled. There are three primary types of metadata, which are as follows.
- Descriptive Metadata
- Administrative Metadata
- Provenance Metadata

Descriptive Metadata includes information that identifies and characterizes the QA artifact. This can consist of details such as test type (functional, regression, etc), test priority (high, medium, low), current status (pass, fail, blocked) and other tags related to specific features or components under test.
Administrative Metadata provides information about the management and governance of the QA artifact. This type includes data such as ownership (who created or who is responsible for the test), creation and modification timestamps, versioning details and access controls.
Lastly, Provenance Metadata captures the history and lifecycle of the QA item. It basically documents how the quality assurance process has evolved over time. For example, it details which teams or automated systems performed updates, results of previous test runs, defect fixes or any transformations applied to the test cases or defects.
These metadata types together improve the management and retrieval of testing assets. Teams are able to achieve better reproducibility and auditability.
Attributes and Example of Metadata Tags
Each meta tag is composed of several key attributes. These attributes are usually a name or a value. Sometimes, additional metadata, such as the owner of the tag or timestamps indicating when it was created or last updated, is also added to the attributes.

Below is a closer look at some of the most used meta tags in software QA.
1. Priority
The priority tag defines the importance and urgency of a test case or defect. Levels typically set as high, medium or low are given to this tag.
High-priority tags indicate critical functionality that must be tested thoroughly and frequently. On the other hand, low-priority tags correspond to less critical or optional features.
Assigning priority helps teams focus limited QA resources where they matter most. Risk management and severe issues are addressed promptly due to this.
A report by the National Institute of Standards and Technology shows that prioritizing defects and tests effectively can accelerate defect resolution time by up to 35%. Consequently, the overall time to market is reduced
2. Test Type
This tag categorizes test cases based on their nature and purpose. For example, functional, regression or smoke tests.
Functional tests verify specific functionalities against requirements, while regression tests ensure that recent changes have not broken existing features. Lastly, smoke tests provide a quick check for critical functionalities in a new build.
Proper use of these test-type tags supports constructing targeted test suites, managing automation strategies and tracking coverage across different testing phases.
3. Component
Component tagging links QA artifacts to the relevant system parts. These parts are the user interface (UI), backend, or application programming interface (API).
This sort of granularity enables defect triage and test execution to be managed at the component level. Faster issue localization and specialized testing are facilitated with it.
It is worth noting that as large systems grow, component-based tagging plays a huge role in scaling QA efforts efficiently.
4. Automation Status
Automation status tags identify whether a test case is automated or manual. They provide visibility into automation progress and gaps.
Furthermore, it becomes easier for QA teams to report automation coverage and direct manual testing efforts to areas that are yet to be automated. Not to mention the integration of metadata with CI/CD pipelines.
As per the experience report on test automation process improvement by Yuqing Wang and others, organizations that actively track automation status tags report up to a 40% improvement in test execution speed and consistency. This happens because they are able to better plan and reduce manual intervention.
5. Additional Attributes
Beyond these core tags, metadata attributes often include other details. Like “created by” (author of the test or defect), “last updated” timestamps (reflecting the most recent modifications) and “associated test run” identifiers (linking tests to specific executions), as we mentioned above.
These attributes are essential for auditability and accountability. Historical tracking of QA activities also becomes easier. You can ensure that the test artifacts remain reliable and transparent over time.
Consider a test case designed to verify the login functionality of a web application. The test case can be tagged with the following metadata attributes.
Dynamics of Test Execution
- Priority: High – Signalling the critical nature of the login feature and mandating thorough testing every build.
- Test Type: Functional – Denoting that the test verifies specific app functionality.
- Component: UI – Indicating that this test targets the user interface component.
- Automation Status: Automated – Specifying that this test is automated and can be included in continuous integration cycles.
- Created by: QA Lead Alice
- Last updated: 2025-11-05
- Associated test run: Build #1543 Regression

All these meta tags contribute to the QA team quickly pulling all high-priority functional UI tests. Especially ones that have been automated to include in nightly regression runs. They can also track ownership and update history.
Core Architecture and Data Contract Configuration for Metadata Tagging
A good core architecture, paired with strict data contract management, is needed to do effective software QA metadata tagging. This setup ensures that metadata remains consistent and reliable.
The following things are needed for a top-notch data contract configuration.
- Standardized Metadata Schema: Defines the structure, fields, and allowed values for metadata tags. It ensures consistency in creation and updates across test management, defect tracking and automation platforms.
- Data Contracts: These are the formal agreements and validation protocols that govern metadata formats and synchronization. Data contracts also make it easier to update rules to prevent write-back errors and conflicting tags.
- Metadata Hierarchies: The inheritable tags where metadata is assigned to higher-level entities. Such as test suites or requirements. This automatically cascades to child artifacts, reducing manual tagging effort and enforcing uniformity.
- Scalability and Future-readiness: This architecture and contract approach make metadata tagging adaptable to growing repositories and evolving project requirements.
The article on metadata management in data governance by Arzu Teymurova indicates that organizations that implement such structured metadata governance reduce metadata-related errors by up to 30%. They improve test management efficiency by 25-35% and achieve smoother audits and compliance processes.

Metadata Tagging and User Bucketing for Personalization
User bucketing in software QA involves grouping test cases, as well as defects and other QA artifacts. This is done based on metadata such as team roles, environments or application modules.
QA teams can assign buckets to individual testers (i.e., all tests owned by QA engineer Alice), automated test suites or environment-specific test sets (for example, tests for staging or mobile).
This segmentation leads to better workload distribution. Along with clear accountability and optimized test runs tailored to the expertise and responsibilities of each team member.
Role-based buckets support collaboration in distributed teams as they deliver only the relevant bucketed content to each user. Teams also don’t get overwhelmed this way.
Additionally, bucketing improves reporting by enabling targeted performance and progress views aligned with user or team focus areas.
To exemplify user bucketing for personalization, think of a payment gateway module. It may have a dedicated bucket containing all associated tests assigned to a particular tester. Execution and issue management will be simplified, which is particularly beneficial in that critical domain.
Handling Bucket Thresholds: Strategies for Less Than 1,000 and More Than 1,000 Buckets
Managing metadata buckets efficiently is very important as QA repositories grow from small to enterprise scale.
The thing is, in repositories with fewer than 1,000 buckets or tags, manual tagging combined with dynamic filters often suffices to maintain order and usability. It’s easy for teams to track and organize metadata without overly complex automation.
However, as the volume of buckets exceeds 1,000, challenges surface. Some of which are:
- Difficulty in metadata retrieval
- Increases tag duplication
- User navigation frustrations
To overcome these hurdles and keep metadata systems scalable and responsive, we recommend you follow these practices:
- Employ automated bulk tagging tools to reduce manual effort and chances of human error. Automation ensures that tagging is applied consistently and quickly across large datasets.
- Implement tag normalization protocols to enforce a controlled vocabulary. This minimizes duplicate or inconsistent tags created by different teams or tools. The overall metadata quality is improved as well.
- Optimize metadata storage and retrieval with efficient indexing strategies in underlying databases. Proper indexing dramatically speeds up searches and filters.
- Continuously monitor and audit metadata quality to catch and resolve anomalies early. Doing so will maintain confidence in metadata-driven reports.
Improve your QA with a Kualitee, built for metadata-driven reporting. Discover Kualitee’s metadata strategy and platform features today.
Machine Learning Integration: Mapping User Metadata Values and TagIDs
Artificial intelligence and machine learning have come a long way. They are now being used to automate the classification and assignment of metadata tags.
ML models analyze historical tagging patterns and test contexts. As well as user interactions to suggest or automatically apply the most relevant metadata tags. This makes it easier to maintain organized and reliable QA repositories.
With that said, the key benefits of ML-driven metadata tagging are as follows.
- Time savings: The paper on automating workflows and enhancing user experience mentions that ML reduces manual metadata tagging efforts by 30-50%. This accelerates metadata assignment and enables QA teams to focus on higher-value testing activities.
- Improved accuracy: By learning from past tagging decisions and contextual cues, ML helps standardize tag application. It minimizes inconsistencies that are often introduced by manual processes.
- Advanced analytics: Automated and consistent metadata enables sophisticated analysis such as predictive test impact assessment. This helps teams prioritize tests that are most likely to detect defects based on historical data and system changes.
- Scalability: ML systems can handle large volumes of new or evolving test cases with minimal human intervention. They support continuous integration and deployment pipelines.
In practical terms, ML-powered tagging workflows often leverage natural language processing (NLP) to comprehend test case descriptions. As well as defect reports and related documents.
They may also combine multi-modal data analysis (text, images, logs) to create rich, accurate metadata. These systems generally employ confidence scoring to decide which tags to apply automatically and which to flag for human review.
One thing you should note is that, despite its power, ML-driven metadata tagging works best when combined with human oversight. It’s meant to complement you, not replace you.
Practical Applications of Metadata Tagging
Metadata tagging significantly improves multiple elements in software quality assurance. It drives improvements that directly impact efficiency and decision-making.
Some real-world applications of strategic tagging that lead to measurable gains are as follows.
Dynamic Test Execution
By tagging tests with relevant attributes such as target environment or specific features, teams implement conditional test runs. Doing so helps them ensure that automation resources focus on high-value tests and reduce the execution time, along with feedback cycles.
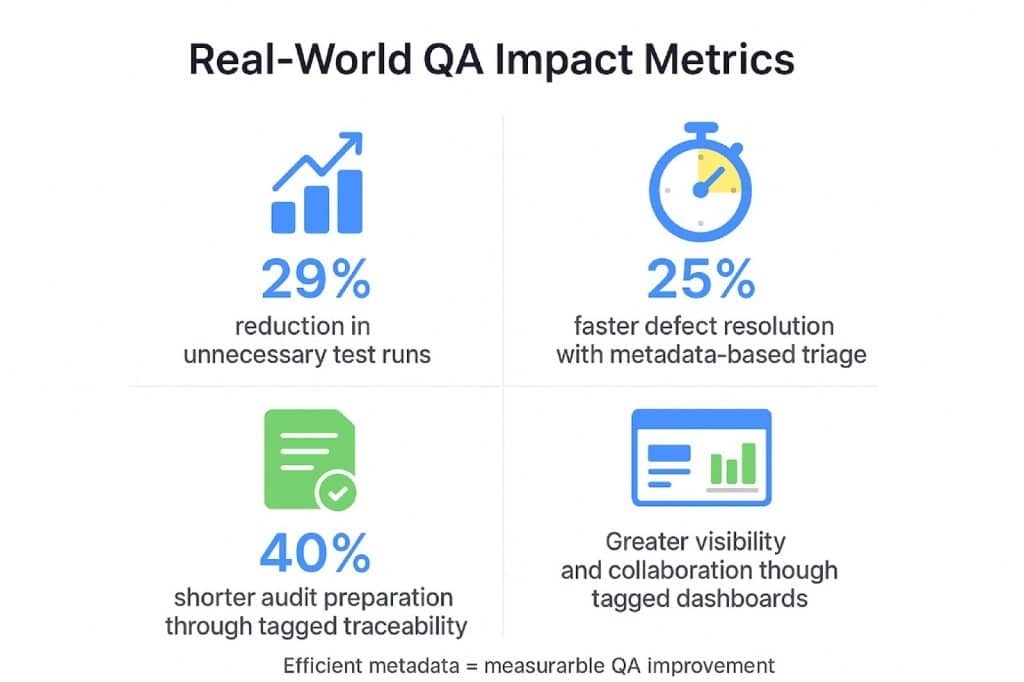
For example, tagging tests to run only in production or staging environments cuts unnecessary test runs by 29%, accelerating release velocity.
Defect Triage
Testers add metadata tags indicating defect priority, module or root cause, enabling quick routing to the correct developers or relevant teams. Such targeted triage increases the issue resolution rate and reduces defect backlog.
Research by John A Whitaker and others on the correlation between observability metrics and mean time to recovery (MTTR) indicates that effective metadata-driven triage can decrease mean time to resolution (MTTR) by as much as 25% in large organization.
Defect Triage
Requirements, test cases and defects are connected with consistent metadata so coverage completeness can be achieved. It also supports audit preparedness. Traceability matrices enriched with tags reduce compliance audit times by 40%.
They help organizations maintain top regulatory standards, especially in finance and healthcare.
Reporting and Dashboards
Metadata filters help to customize dashboards. This is done to provide stakeholders with relevant views tailored to their interests. Whether they want to look at the tasks assigned to management, QA teams or development.
These targeted reports improve transparency, as well as risk management. Enterprises that use metadata-based reporting are bound to see improvements in stakeholder engagement and faster project turnaround.
Best Practices and Tips for Effective Metadata Tagging
Successful metadata tagging relies on a structured and disciplined approach. And this is because consistency and usefulness across software QA environments need to be ensured.
We recommend the following practices to achieve this target.
Define Controlled Vocabularies
Controlled vocabularies are essential to ensure consistency in metadata tagging. You need it to eliminate all confusion from synonyms or varying terminology by standardizing tag names and values across the QA team.
This uniformity improves search accuracy and metadata reliability. It becomes easier for you to locate and group related artifacts efficiently.
Regularly Review and Update Tag Schemas
Metadata needs to evolve alongside projects. Regularly review and update tag schemas to keep metadata relevant and aligned with current quality goals.
This ongoing maintenance helps you prevent schema obsolescence and reduces clutter as well. It also ensures that tags continue to support effective filtering, reporting and traceability.
Automate Enforcement Through Tool Integrations
Automation through integrated tools facilitates real-time validation and enforcement of tagging rules. So, do it.
This reduces human errors such as inconsistent tag formats or missing attributes. Furthermore, automated checks within test management and defect tracking platforms improve metadata integrity. And not just that, they reduce manual tagging burdens too.
Provide Clear Team Training and Documentation
Continuously Monitor Tag Usage with Audit Tools
Educate all QA stakeholders on the importance of metadata tagging and how to correctly apply tags. Doing so will promote consistent usage.
Comprehensive documentation and training materials make it easier for team members to follow best practices. Variation and misunderstandings about metadata protocols are also reduced.
Continuously Monitor Tag Usage with Audit Tools
Regular auditing uncovers issues like tag misuse, redundancy and inconsistent application early.
Use monitoring tools to enable QA leadership so governance can be maintained and metadata health can be improved. Lastly, implement corrections proactively before any issues impact reporting or traceability.
Establish Metadata Governance Policies
Formal governance clarifies roles and responsibilities for metadata creation, review and maintenance.
You should create governance policies that support sustained metadata quality by defining ownership. Along with review cycles and escalation paths for conflicts or uncertainties.
Use AI and Machine Learning for Tagging Assistance
AI-driven auto-tagging tools augment manual efforts. They do it by suggesting or automatically applying tags based on historical data patterns.
Similarly, machine learning models improve consistency and reduce tagging time significantly. They help you scale efficiently with growing projects. Metadata management becomes agile and sustainable with them.
Hence, try to use them wherever you can to get some load off your shoulders.
Validating and Evaluating Meta Tags
Validation frameworks play a critical role in ensuring the quality and reliability of metadata used in software testing.
They focus on examining metadata for completeness, accuracy and logical consistency. This directly impacts the effectiveness of test execution and traceability.
With that said, a good validation approach typically includes automated tools that generate reports. These reports pinpoint missing tags, conflicting values, obsolete metadata and deviations from established schemas.
The key validation criteria cover the following things.
- Completeness: Always verify that all mandatory metadata fields are present. Such as test environment, priority and component tags. This way, gaps that impair test selection and reporting are avoided.
- Accuracy: Check that metadata values conform to expected formats and controlled vocabularies. You want to reduce ambiguities and ensure consistency across QA assets, and this is the way.
- Logical Consistency: Make sure that all related metadata elements don’t contradict each other. For example, a tag indicating both “priority: high” and “status: deferred.” This could cause confusion.
Using Metadata Tagging for QA Client Onboarding and Document Management
The benefits of metadata tagging aren’t just limited to decision-making and traceability. It can also make client onboarding and optimizing document management workflows easier.
By attaching contextual tags to documents, test reports, approvals and other client-related artifacts, organizations are able to create an organized information ecosystem. Everything in this ecosystem is searchable and traceable.
The main benefit of metadata-driven onboarding includes significantly faster document retrieval times. This directly translates into accelerated onboarding cycles and enables teams to engage clients more quickly.
Furthermore, metadata tagging improves collaboration by allowing multiple stakeholders to locate and work on the exact documents they need without confusion or redundant efforts.
On the compliance front, assigning tags related to regulatory requirements and confidentiality ensures audit readiness. It also reduces the risk of overlooked documentation.
Take a firm that uses metadata tagging to automate document sorting and routing, for example. Automated systems extract key data points from uploaded files and assign tags. These tags trigger sequential workflows such as routing contracts labeled “Needs Legal Review” directly to the legal team. This end-to-end automation minimizes manual errors and follow-up delays.
Bring Metadata Tagging to Life with Kualitee
Implementing metadata tagging effectively requires a unified system. One that connects testing activities and enforces tag consistency, along with delivering traceable insights in real time. This is where Kualitee makes the difference for you.
Kualitee enables teams to operationalize metadata tagging with features like:
- AI-Powered Tagging & Test Generation (Hootie): It helps reduce repetitive tagging, along with test case creation, and analyzes test context for you. Maintaining accuracy across QA repositories has never been easier.
- Requirement Traceability Matrix: Kualitee establishes end-to-end visibility between requirements, test cases and defects. This ensures compliance and coverage.
- Custom Reporting Dashboards: Allows stakeholders to filter, segment, as well as visualize QA metrics based on tags for faster decisions.
- Integrated Defect and Test Management: Kualitee maintains metadata continuity across CI/CD pipelines. You can link every test and defect with contextual data.
Kualitee turns metadata tagging from a theoretical concept into a practical framework. Get traceability and automation for smarter QA management at your fingertips.
Sign up today for a 14-day free trial. No credit card required.
Conclusion
Metadata tagging isn’t just a supportive practice. It is essential to fulfill today’s software quality assurance demands. That’s because it brings order to complexity and connects QA artifacts through context. Every test, defect and requirement contributes to a unified quality strategy if metadata tagging is done right.
The correct way to go about it is by implementing clear governance and controlled vocabularies, along with automation.
Furthermore, metadata tagging strengthens visibility, accelerates decision-making and supports traceability across the entire QA cycle. You can integrate machine learning and AI to further amplify these gains by reducing manual tagging effort.
QA environments continue to scale. And organizations that invest in structured metadata governance and ML-assisted tagging will definitely achieve faster test execution. They will have smoother audits and more data-driven quality outcomes.
See how Kualitee’s platform centralizes your metadata tagging for better traceability and data-driven quality outcomes. Book your Free Demo today!
Frequently Asked Questions (FAQs)
Q) What is Metadata Tagging?
Software QA metadata tagging is the process of assigning descriptive labels or tags to test cases, defects, requirements and other QA artifacts. These tags capture important context like test priority, module, environment or ownership. They improve organization, searchability, traceability and reporting efficiency.
Q) What are the Three Types of Metadata?
The three types of metadata are:
- Descriptive Metadata: Identifies and characterizes QA artifacts. Such as test type, priority and status.
- Administrative Metadata: Covers management details like ownership, timestamps, versioning and access controls.
- Provenance Metadata: Captures the history and lifecycle of the QA item, including updates, test results and defect fixes.
Q) What is an Example of a Metadata Tag?
An example metadata tag in QA can be “Environment: Staging,” which helps associate test cases or defects with the staging environment. Other common tags include “Priority: High,” “Module: Login,” or “Status: In Progress.”
Q) What are the Four Attributes Available for Metadata Tags?
Usually, metadata tags have these attributes:
- Name: Defines the type of metadata (priority, environment, etc).
- Value/Content: The specific entry for the tag (e.g., High, Production).
- Scope/Context: Indicates the applicable context, such as the project or test cycle name.
Timestamp/Date: Records when the tag was applied or last updated.




